
機(jī)器學(xué)習(xí) (ML)正在改變各行各業(yè),它能夠開發(fā)復(fù)雜的模型來分析大量數(shù)據(jù)并做出準(zhǔn)確的預(yù)測。TensorFlow是一種流行的開源 ML 框架,已成為研究人員和開發(fā)人員的強(qiáng)大工具。
TensorFlow 利用圖形處理單元 (GPU)的計算能力來加速深度學(xué)習(xí)模型的訓(xùn)練和推理過程。如前所述,GPU 擅長并行處理,使其成為處理 ML 任務(wù)所需的密集計算的理想選擇。領(lǐng)先的 GPU 制造商 NVIDIA 提供了一系列專為機(jī)器學(xué)習(xí)工作負(fù)載設(shè)計的高性能選項。
在本文中,我們將比較 NVIDIA A4000 和 A5000 GPU。兩者都是NVIDIA 安培架構(gòu)的一部分,與前幾代相比,該架構(gòu)提供了顯著的性能改進(jìn)。我們的比較將評估它們在運行 TensorFlow 時的性能,并深入了解哪種 GPU 在各種機(jī)器學(xué)習(xí)任務(wù)中表現(xiàn)更好。
為什么使用 GPU 來完成機(jī)器學(xué)習(xí)任務(wù)?
我們已經(jīng)廣泛討論了 GPU 如何通過并行處理能力徹底改變機(jī)器學(xué)習(xí)和深度學(xué)習(xí)。憑借數(shù)千個核心,GPU 可以滿足大規(guī)模機(jī)器學(xué)習(xí)算法的計算需求,從而實現(xiàn)更快的訓(xùn)練、更快的模型開發(fā)以及高效處理復(fù)雜計算。
GPU 專為處理機(jī)器學(xué)習(xí)中常見的矩陣乘法和浮點計算而設(shè)計,非常適合數(shù)據(jù)密集型任務(wù)。通過利用 GPU,研究人員和開發(fā)人員可以管理海量數(shù)據(jù)集并加速訓(xùn)練和推理過程,最終推動機(jī)器學(xué)習(xí)領(lǐng)域的發(fā)展。
什么是 TensorFlow?
TensorFlow 是一個廣泛使用的開源機(jī)器學(xué)習(xí)框架,受到研究人員、開發(fā)人員和行業(yè)專業(yè)人士的青睞。它為構(gòu)建、訓(xùn)練和部署各種機(jī)器學(xué)習(xí)模型(包括神經(jīng)網(wǎng)絡(luò))提供了一個全面的生態(tài)系統(tǒng)。
TensorFlow 的底層實現(xiàn)是使用多維數(shù)組(稱為張量)來定義和操作數(shù)學(xué)運算。這些張量在計算圖中移動,其中節(jié)點表示運算,邊表示數(shù)據(jù)依賴關(guān)系。這種基于圖的方法可以實現(xiàn)高效的并行計算,使 TensorFlow 成為大規(guī)模數(shù)據(jù)處理和復(fù)雜數(shù)學(xué)運算的理想選擇。
TensorFlow 具有高級 API,可簡化機(jī)器學(xué)習(xí)模型的創(chuàng)建和訓(xùn)練。用戶可以從各種預(yù)構(gòu)建的層、激活函數(shù)和優(yōu)化算法中進(jìn)行選擇,也可以創(chuàng)建自定義組件以滿足其特定需求。此外,TensorFlow 支持多種數(shù)據(jù)格式,并與其他流行庫(如NumPy和Pandas)無縫集成,從而方便將其納入現(xiàn)有工作流程。
TensorFlow 的一個顯著優(yōu)勢是它能夠利用 GPU 來加速機(jī)器學(xué)習(xí)任務(wù)。它與 NVIDIA GPU 的兼容性尤其值得注意。NVIDIA 提供了 GPU 加速庫,如計算統(tǒng)一設(shè)備架構(gòu) (CUDA)和CUDA 深度神經(jīng)網(wǎng)絡(luò) (cuDNN),TensorFlow 使用這些庫在 NVIDIA GPU 上高效執(zhí)行計算。
CUDA是一個并行計算平臺和 API,可讓開發(fā)人員充分利用 NVIDIA GPU。得益于其大規(guī)模并行架構(gòu),TensorFlow 使用 CUDA 將計算密集型操作卸載到 GPU。這種 GPU 加速大大加快了訓(xùn)練和推理過程,從而加快了模型開發(fā)和部署速度。
另一方面,cuDNN是一個專為深度神經(jīng)網(wǎng)絡(luò)設(shè)計的 GPU 加速庫。它提供了卷積和池化等基本操作的高度優(yōu)化實現(xiàn),使 TensorFlow 在 NVIDIA GPU 上運行時能夠?qū)崿F(xiàn)更高的性能。
通過 CUDA 和 cuDNN 利用 GPU,TensorFlow 可幫助機(jī)器學(xué)習(xí)從業(yè)者訓(xùn)練更復(fù)雜的模型、處理更大的數(shù)據(jù)集并更快地獲得結(jié)果。此功能確保 TensorFlow 始終處于先進(jìn)機(jī)器學(xué)習(xí)研究和開發(fā)的前沿。
NVIDIA A4000 和 A5000 的規(guī)格
NVIDIA A4000 和 A5000 GPU 屬于 Ampere 架構(gòu)的一部分,與前幾代產(chǎn)品相比,性能顯著提升。這些 GPU 專為滿足機(jī)器學(xué)習(xí)任務(wù)(包括使用 TensorFlow 的任務(wù))的苛刻要求而量身定制。
以下是與機(jī)器學(xué)習(xí)相關(guān)的關(guān)鍵技術(shù)規(guī)格:
NVIDIA A4000:
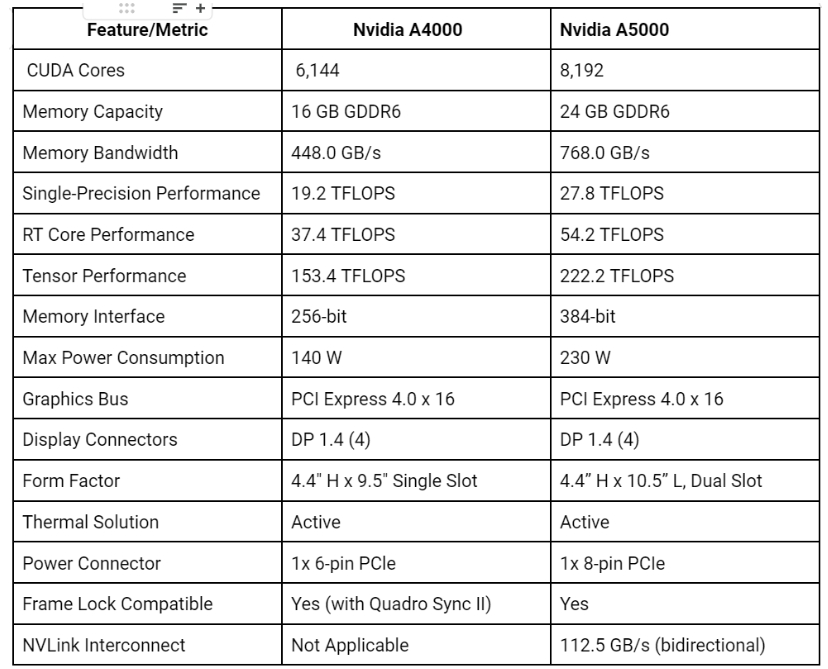
內(nèi)存帶寬:高達(dá) 512 GB/s
CUDA 核心數(shù): 6144
張量核心: 192
最大功耗: 140W
內(nèi)存大小: 16GB GDDR6
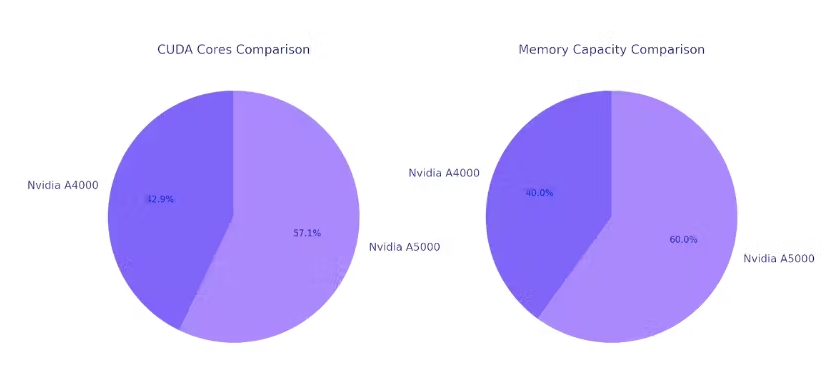
NVIDIA A5000:
內(nèi)存帶寬:高達(dá) 768 GB/s
CUDA 核心數(shù): 8192
張量核心: 256
最大功耗: 230W
內(nèi)存大小: 24GB GDDR6
兩款 GPU 都具有大量內(nèi)存帶寬,這對于高效地將數(shù)據(jù)傳送到計算核心至關(guān)重要。A5000 擁有更多 CUDA 核心,可以同時管理更多并行任務(wù),從而可能縮短訓(xùn)練和推理時間。此外,兩款 GPU 中的張量核心都有助于加速混合精度運算,這在深度學(xué)習(xí)中很常用。
TensorFlow 中 A4000 與 A5000 的比較分析
與 NVIDIA A4000 相比,A5000 提供更多 CUDA 核心、更大的內(nèi)存容量和更高的內(nèi)存帶寬。這些增強(qiáng)的規(guī)格使 A5000 成為更密集的計算任務(wù)的理想選擇,特別是在 AI 研究、數(shù)據(jù)科學(xué)和高級設(shè)計可視化領(lǐng)域。以下是主要區(qū)別:
架構(gòu)和制造工藝:這兩款 GPU 均基于 Ampere 架構(gòu),這增強(qiáng)了它們有效處理并行處理和復(fù)雜圖形和 AI 計算的能力。
性能核心: A5000 具有更多 CUDA 核心(8,192 個 vs. 6,144 個),這對于并行處理和加速計算任務(wù)至關(guān)重要。核心數(shù)量的增加可以帶來更好的性能。
內(nèi)存:與 A4000 的 16 GB 相比,A5000 提供更大的 24 GB GDDR6 內(nèi)存容量。此外,A5000 的內(nèi)存帶寬更高,為 768 GB/s,而 A4000 為 448 GB/s。這使得 A5000 能夠管理更大的數(shù)據(jù)集并實現(xiàn)更快的數(shù)據(jù)傳輸速率。
功耗: A5000 的功耗率為 230 W,高于 A4000 的 140 W。這種增加的功耗可能需要更強(qiáng)大的冷卻解決方案,對于系統(tǒng)構(gòu)建者來說,這是一個重要的考慮因素。
目標(biāo)應(yīng)用:雖然這兩種 GPU 都是為專業(yè)環(huán)境中的高性能計算而設(shè)計的,但 A5000 擁有更大的 CUDA 核心數(shù)量、更大的內(nèi)存容量和更高的內(nèi)存帶寬,使其更適合執(zhí)行要求苛刻的任務(wù)和處理更大的數(shù)據(jù)集。
基準(zhǔn)和性能指標(biāo)
在比較用于 TensorFlow 任務(wù)的 GPU 時,幾個性能指標(biāo)至關(guān)重要:
處理速度: GPU 執(zhí)行計算的速度對于減少訓(xùn)練和推理時間至關(guān)重要。具有更多 CUDA 核心和更高時鐘速度的 GPU 通常可提供更快的處理速度。
內(nèi)存利用率: GPU 的內(nèi)存帶寬和容量對于高效處理大型數(shù)據(jù)集至關(guān)重要。更高的內(nèi)存帶寬可以加快與 GPU 之間的數(shù)據(jù)傳輸速度,而更大的內(nèi)存容量則可以處理更廣泛的模型和數(shù)據(jù)集。
電源效率:功耗是一個重要因素,特別是對于大型機(jī)器學(xué)習(xí)項目而言。提供高性能同時最大限度降低功耗的 GPU 可以節(jié)省成本并帶來環(huán)境效益。
這些指標(biāo)共同影響 TensorFlow 任務(wù)的整體性能和有效性,包括訓(xùn)練神經(jīng)網(wǎng)絡(luò)、數(shù)據(jù)處理速度和模型準(zhǔn)確性。
以下是 A4000 和 A5000 的一些關(guān)鍵性能基準(zhǔn):
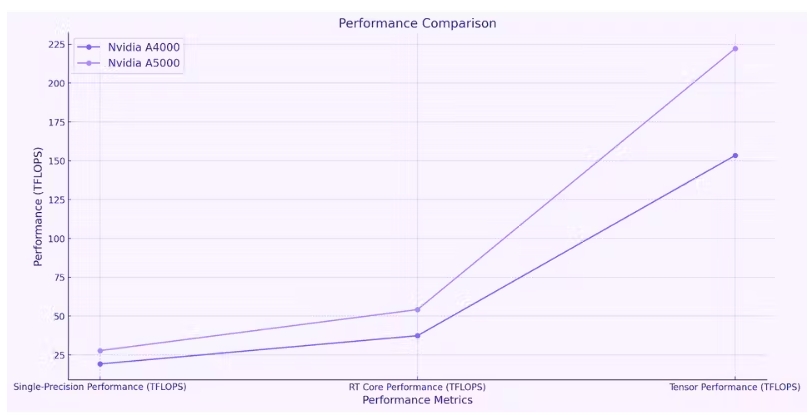
NVIDIA A4000 和 A5000 GPU 為 TensorFlow 任務(wù)提供了強(qiáng)大的計算能力,其中 A5000 在大多數(shù)指標(biāo)上的表現(xiàn)通常優(yōu)于 A4000。這兩款 GPU 都具有大量 CUDA 核心,這些核心是并行處理器,可大大加速計算任務(wù)。不過,A5000 的數(shù)量為 8192,而 A4000 的數(shù)量為 6144。
在內(nèi)存容量方面,A5000 的 24 GB GDDR6 超過了 A4000 的 16 GB,使其能夠在 GPU 內(nèi)存中容納更多數(shù)據(jù),這對于大規(guī)模 TensorFlow 任務(wù)尤其有利。
內(nèi)存帶寬(衡量從 GPU 內(nèi)存讀取或?qū)懭霐?shù)據(jù)的速度)在 A5000(768 GB/s)中也高于 A4000(448 GB/s)。就單精度性能(衡量 GPU 執(zhí)行浮點計算的速度)而言,A5000 的表現(xiàn)優(yōu)于 A4000,提供 27.8 TFLOPS,而 A4000 為 19.2 TFLOPS。
與 A4000(37.4 TFLOPS)相比,A5000 還具有卓越的 RT Core 性能(54.2 TFLOPS),表明光線追蹤能力更佳。
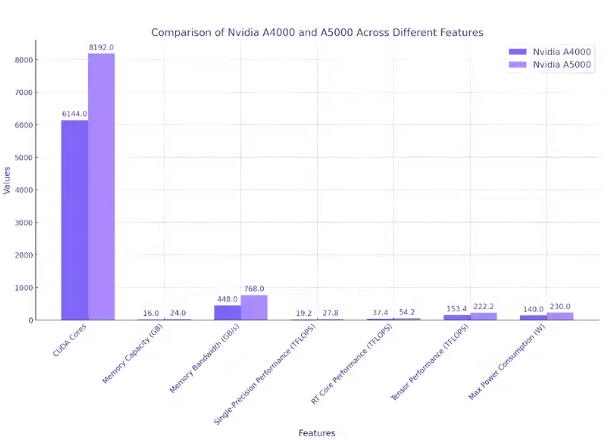
張量性能(衡量張量運算效率)是 A5000 的另一個出色領(lǐng)域。它提供 222.2 TFLOPS,明顯高于 A4000 的 153.4 TFLOPS。A5000 確實消耗更多電量,最大消耗為 230 W,而 A4000 為 140 W。
兩款 GPU 均配備四個 DP 1.4 顯示連接器,但 A5000 的外形尺寸更大,需要更強(qiáng)大的電源連接器(1 個 8 針 PCIe,而 A4000 為 1 個 6 針 PCIe)。雖然兩款 GPU 都兼容幀鎖,但只有 A5000 支持 NVLink Interconnect,提供 112.5 GB/s(雙向)的速度。
總體而言,這兩款 GPU 都非常適合 TensorFlow 任務(wù),但 A5000 在多個指標(biāo)上通常都表現(xiàn)優(yōu)異。然而,這種增強(qiáng)的性能是以更高的功耗為代價的。
關(guān)于 A4000 和 A5000 用于機(jī)器學(xué)習(xí)的最終想法
由于規(guī)格不同,NVIDIA A4000 和 A5000 GPU 的 TensorFlow 性能也有所不同。A5000 擁有更多 CUDA 核心和更大內(nèi)存,在需要大量并行處理和大數(shù)據(jù)集處理的任務(wù)(例如訓(xùn)練復(fù)雜的深度學(xué)習(xí)模型)中表現(xiàn)出色。相比之下,由于功耗較低,A4000 對于要求不高的任務(wù)效率更高。對于大型數(shù)據(jù)集,A5000 的更大內(nèi)存和更高帶寬可以縮短計算時間,而這兩種 GPU 都可以為較小的數(shù)據(jù)集提供令人滿意的性能。
因此,兩者之間的選擇取決于任務(wù)的具體要求。
為 TensorFlow 項目選擇合適的 GPU 需要考慮性能、成本效益、能耗、使用壽命和可擴(kuò)展性。通過評估這些因素并了解 GPU 技術(shù)和 TensorFlow 的進(jìn)展,數(shù)據(jù)科學(xué)家和 ML 工程師可以做出明智的決策,以優(yōu)化他們的機(jī)器學(xué)習(xí)工作流程并實現(xiàn)他們的項目目標(biāo)。











