
NVIDIA 在 NVIDIA GTC 2024 上發(fā)布其下一代基于 Blackwell 的 GPU,標(biāo)志著 AI 技術(shù)取得了關(guān)鍵突破。
隨著人工智能和機(jī)器學(xué)習(xí)領(lǐng)域繼續(xù)以驚人的速度發(fā)展,NVIDIA 的最新創(chuàng)新——Blackwell 架構(gòu),將以無(wú)與倫比的并行計(jì)算能力重新定義AI和HPC。
NVIDIA 展示了一系列新技術(shù),有望以前所未有的方式加速 AI 訓(xùn)練和推理。他們推出了 Blackwell GPU、GB200 Super Chip 和GB200 NVL72。每一個(gè)都代表著突破性的創(chuàng)新。
在本文中,我們將深入分析 NVIDIA 的 Blackwell 架構(gòu)。它對(duì)于高性能計(jì)算意味著什么?它如何改進(jìn) Hopper 架構(gòu)?然后,我們將逐一介紹每款新產(chǎn)品。
Blackwell vs Hopper
Blackwell 架構(gòu)以大衛(wèi)·布萊克威爾,受人尊敬的數(shù)學(xué)家和統(tǒng)計(jì)學(xué)家。布萊克威爾在博弈論和統(tǒng)計(jì)學(xué)方面的開(kāi)創(chuàng)性工作和貢獻(xiàn)在該領(lǐng)域留下了不可磨滅的印記,使他的名字成為數(shù)學(xué)科學(xué)創(chuàng)新和卓越的代名詞。這一致敬反映了新平臺(tái)的開(kāi)創(chuàng)性和先進(jìn)的計(jì)算能力。
NVIDIA 的 Blackwell 架構(gòu)將擁有迄今為止最大的芯片,擁有 1040 億個(gè)晶體管。Blackwell GPU(B100 和 B200)采用雙芯片組設(shè)計(jì),與 Hopper 相比有了重大飛躍。例如,B100 的晶體管數(shù)量比 H100 多 1280 億個(gè),AI 性能是 H100 的五倍。
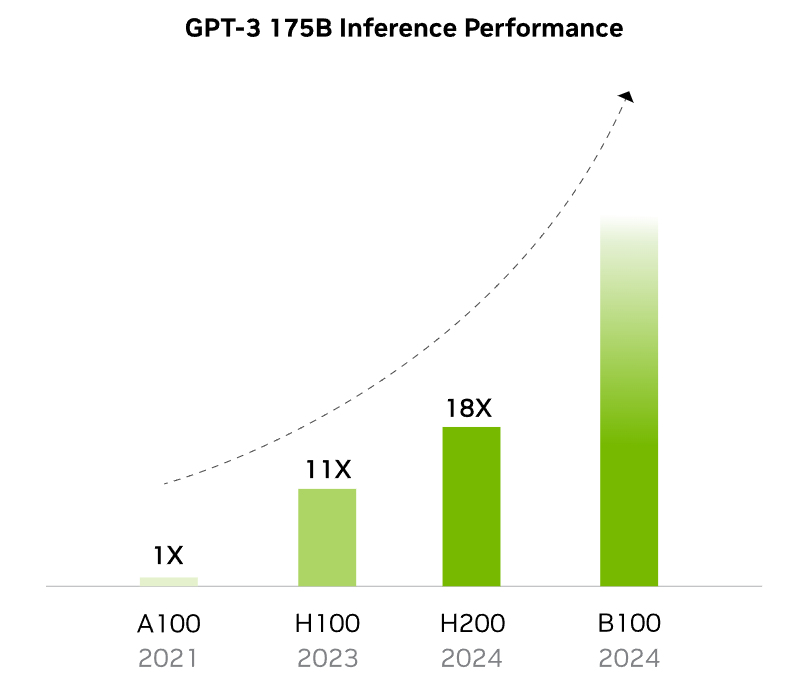
NVIDIA 的 Blackwell GPU 包含 2080 億個(gè)晶體管,采用定制的 TSMC 4NP 工藝制造。所有 Blackwell 產(chǎn)品都采用兩個(gè)光罩限制芯片,通過(guò)每秒 10 兆兆字節(jié) (TB/s) 連接芯片間互連在統(tǒng)一的單個(gè) GPU 中。
Blackwell 架構(gòu)通過(guò)以下方式提供更佳的性能:
FP8性能: Blackwell架構(gòu)在FP8精度下提供20 PetaFLOPS(PFLOPS)的性能,是Hopper架構(gòu)性能的2.5倍。
FP6 性能:與 FP8 一樣,Blackwell 架構(gòu)上的 FP6 性能也是 20 PFLOPS,比 Hopper 架構(gòu)提高了 2.5 倍。
FP4 性能:這是一個(gè)重大飛躍,Blackwell 在新的 FP4 指標(biāo)中提供了 40 PFLOPS,是 Hopper 性能的五倍。這表明它非常重視提高低精度計(jì)算的性能,這對(duì)于 AI 推理至關(guān)重要。
HBM 模型大小: NVIDIA 的 Blackwell 架構(gòu)支持高達(dá) 7400 億個(gè)參數(shù)的模型,這是 Hopper 架構(gòu)所能管理的模型的六倍。這一大幅提升支持開(kāi)發(fā)和運(yùn)行更大、更復(fù)雜的 AI 模型。
HBM 帶寬: Blackwell 上的高帶寬內(nèi)存 (HBM) 帶寬為每參數(shù)秒 34 兆兆字節(jié) (TB/s),是 Hopper 上可用帶寬的五倍。這允許更快的數(shù)據(jù)傳輸速率,從而顯著提高計(jì)算性能。
采用 SHARP 技術(shù)的 NVLink All-Reduce: Blackwell 架構(gòu)采用 SHARP 技術(shù),提供 7.2 TB/s 的 NVLink all-reduce 功能,是 Hopper 架構(gòu)功能的四倍。SHARP(可擴(kuò)展分層聚合和縮減協(xié)議)增強(qiáng)了集體通信操作,這對(duì)于分布式 AI 和機(jī)器學(xué)習(xí)任務(wù)至關(guān)重要。
借助 Blackwell 架構(gòu),NVIDIA 推出了第五代 NVLink,提供前所未有的并行性和帶寬水平,遠(yuǎn)遠(yuǎn)超過(guò) Hopper 架構(gòu)的功能。這些進(jìn)步凸顯了 Blackwell 為下一代人工智能和高性能計(jì)算應(yīng)用提供支持的潛力。
Blackwell 架構(gòu)還配備了 Secure AI。Secure AI 即使在使用時(shí)也能保護(hù)您的 AI 數(shù)據(jù)。它提高了安全性,同時(shí)又不降低速度。這使得公司可以安全地開(kāi)展最復(fù)雜的 AI 項(xiàng)目,保護(hù)他們的想法,并實(shí)現(xiàn)設(shè)備之間的安全訓(xùn)練、分析和信息共享。
Blackwell 還具有智能彈性,配備專用的可靠性、可用性和可服務(wù)性 (RAS) 引擎,可及早識(shí)別可能發(fā)生的潛在故障,從而最大限度地減少停機(jī)時(shí)間。其 RAS 引擎提供深入的診斷信息,以識(shí)別問(wèn)題區(qū)域并規(guī)劃維護(hù)。
NVIDIA 還推出了一套全面的產(chǎn)品,利用 Blackwell 架構(gòu)重塑計(jì)算領(lǐng)域。以下是其中一些產(chǎn)品。
NVIDIA B100 和 B200
NVIDIA 正在 Blackwell 架構(gòu)的基礎(chǔ)上推出兩款新 GPU,即 B100 和 B200。這些 GPU 采用雙芯片設(shè)計(jì),每個(gè)芯片包含四個(gè) HBM3e 內(nèi)存堆棧,每個(gè)堆棧提供 24GB 容量,在 1024 位接口上提供 1 TB/s 的帶寬。
B100 和 B200 GPU 還提高了浮點(diǎn)運(yùn)算的精度。它們配備了一個(gè)轉(zhuǎn)換引擎,可以在可能的情況下動(dòng)態(tài)自動(dòng)地重新縮放數(shù)值精度并將其重新轉(zhuǎn)換為較低的格式。這可以改善機(jī)器學(xué)習(xí)計(jì)算,因?yàn)樵谔幚磔^小的浮點(diǎn)數(shù)時(shí),計(jì)算的準(zhǔn)確性會(huì)影響機(jī)器學(xué)習(xí)模型的能力和準(zhǔn)確性。
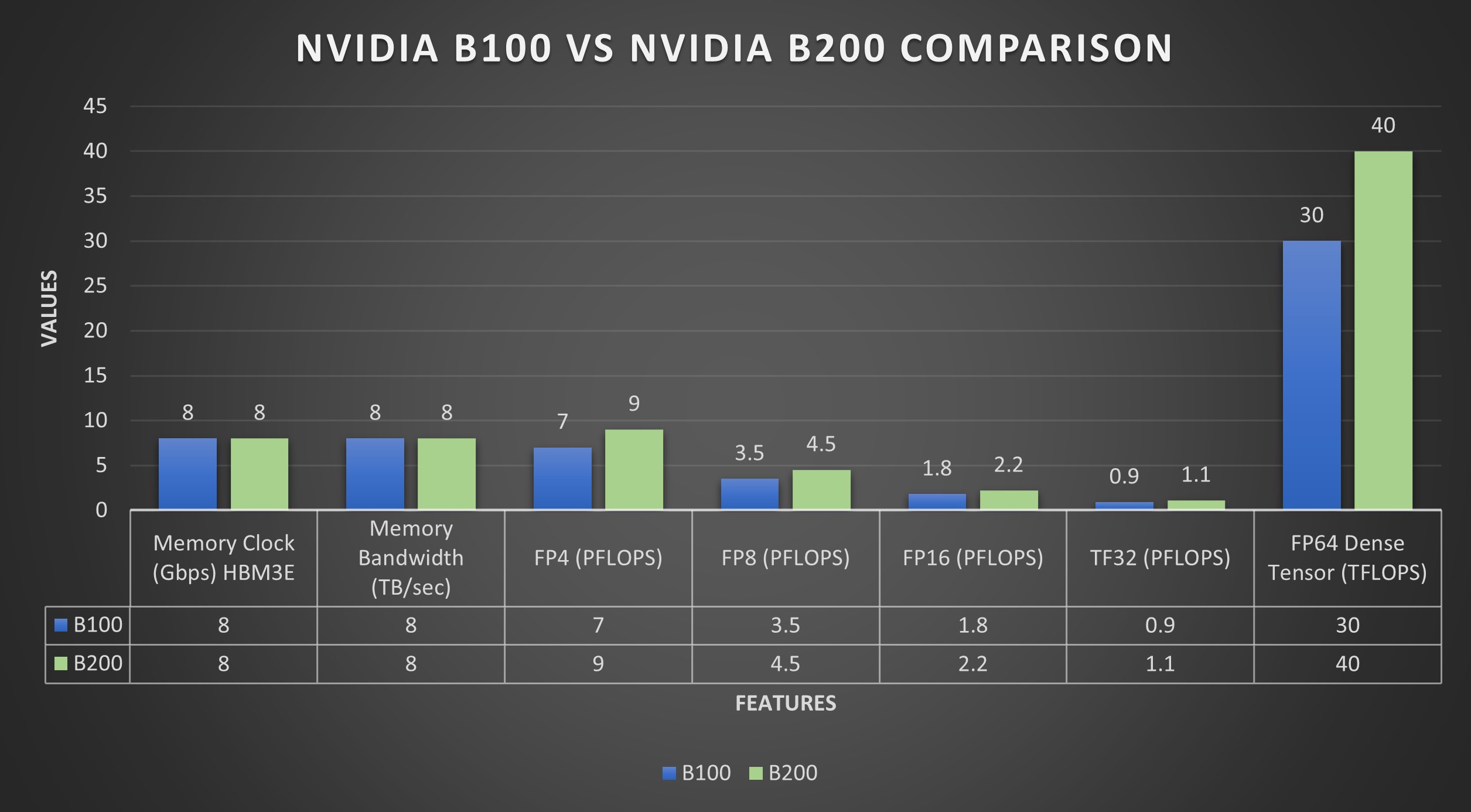
雖然 NVIDIA 沒(méi)有明確提供 B100 和 B200 GPU 的基準(zhǔn)測(cè)試,但我們根據(jù)以下方面細(xì)分了它們的規(guī)格:

NVIDIA B100
B100 Blackwell GPU 提供均衡的計(jì)算效率。它為密集 FP4 張量運(yùn)算提供高達(dá) 7 PFLOPS,其中“密集”表示張量的大多數(shù)元素都非零,需要進(jìn)行全面計(jì)算。相比之下,它為稀疏 FP4 運(yùn)算提供高達(dá) 14 PFLOPS,其中“稀疏”表示大多數(shù)元素為零,由于需要計(jì)算的非零元素較少,因此可以實(shí)現(xiàn)優(yōu)化、更快的處理。
對(duì)于平衡精度和計(jì)算速度至關(guān)重要的 FP6/FP8 張量,B100 在密集/稀疏任務(wù)中分別達(dá)到 3.5/7 PFLOPS。其對(duì)快速數(shù)據(jù)推理至關(guān)重要的 INT8 張量性能在密集/稀疏場(chǎng)景中達(dá)到 3.5/7 POPS。
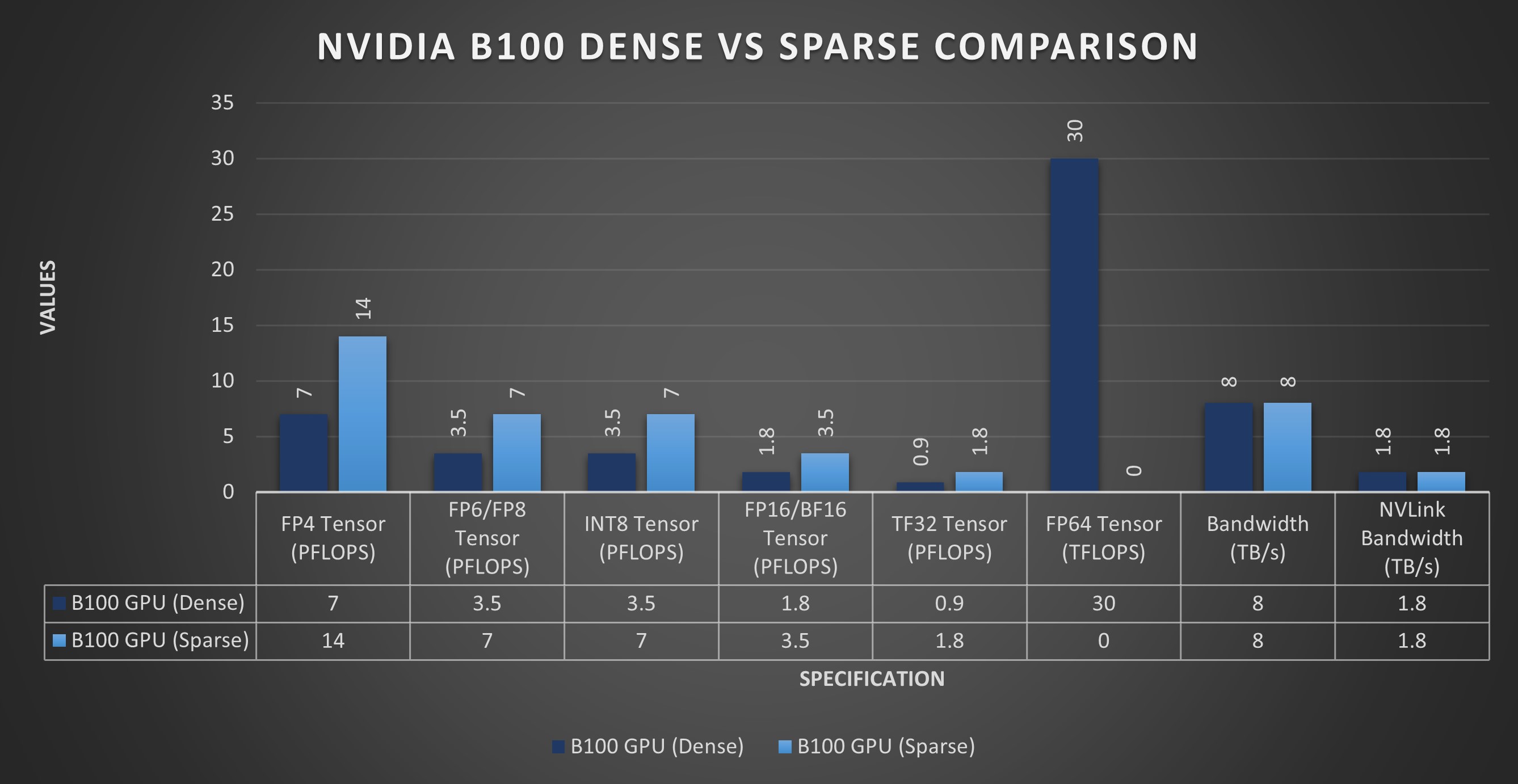
在更高精度要求下,B100 的 FP16/BF16 張量在密集/稀疏計(jì)算中以 1.8/3.5 PFLOPS 運(yùn)行,TF32 張量以 0.9/1.8 PFLOPS 運(yùn)行,支持一系列精確計(jì)算任務(wù)。此外,它還為需要最高精度的科學(xué)應(yīng)用提供 30 TFLOPS 的 FP64 密集計(jì)算。
GPU 擁有 192GB 內(nèi)存,可處理大量數(shù)據(jù)。它支持 8 TB/s 內(nèi)存帶寬和等效 1.8 TB/s NVLink 帶寬,可實(shí)現(xiàn)快速數(shù)據(jù)通信。B100 的功率規(guī)格為 700W,對(duì)于需要平衡功率和性能的復(fù)雜計(jì)算設(shè)置而言,它是一種節(jié)能的選擇。
NVIDIA B200
B200 Blackwell GPU 在密集 FP4 張量運(yùn)算中實(shí)現(xiàn)高達(dá) 9 PFLOPS,在稀疏 FP4 張量運(yùn)算中實(shí)現(xiàn)高達(dá) 18 PFLOPS。對(duì)于 FP6/FP8 張量運(yùn)算,在精度和速度之間取得平衡,B200 分別記錄了密集/稀疏活動(dòng)的 4.5/9 PFLOPS。其 INT8 張量能力對(duì)于快速數(shù)據(jù)分析和推理至關(guān)重要,在密集/稀疏計(jì)算中達(dá)到 4.5/9 POPS,確保高效的實(shí)時(shí)處理。
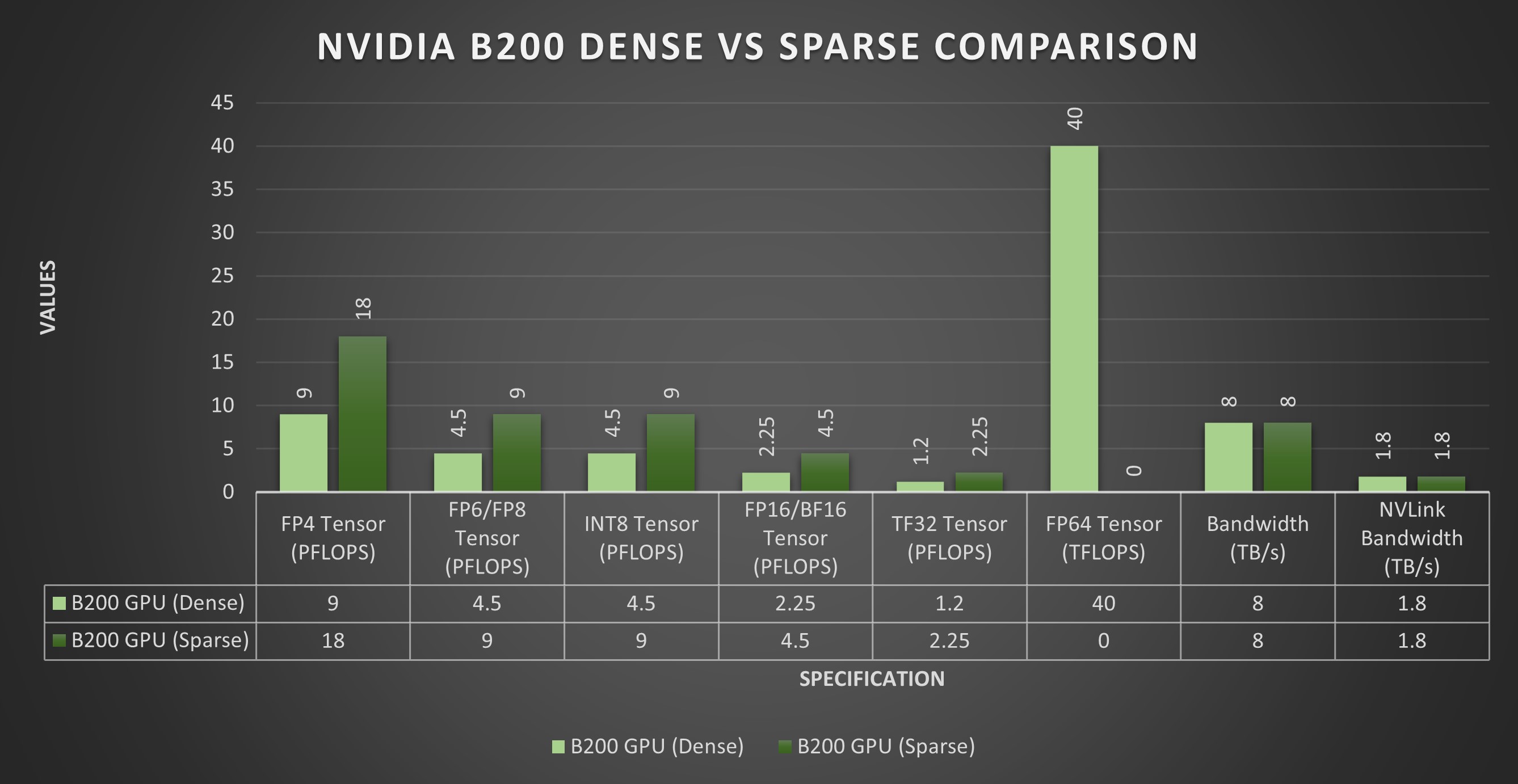
B200 在精密任務(wù)中表現(xiàn)出色,密集/稀疏 FP16/BF16 張量為 2.25/4.5 PFLOPS,密集/稀疏 TF32 張量為 1.2/2.25 PFLOPS,適用于各種科學(xué)和機(jī)器學(xué)習(xí)應(yīng)用。對(duì)于最終精度,例如在詳細(xì)的科學(xué)計(jì)算中,它在 FP64 密集計(jì)算中提供了穩(wěn)定的 40 TFLOPS。
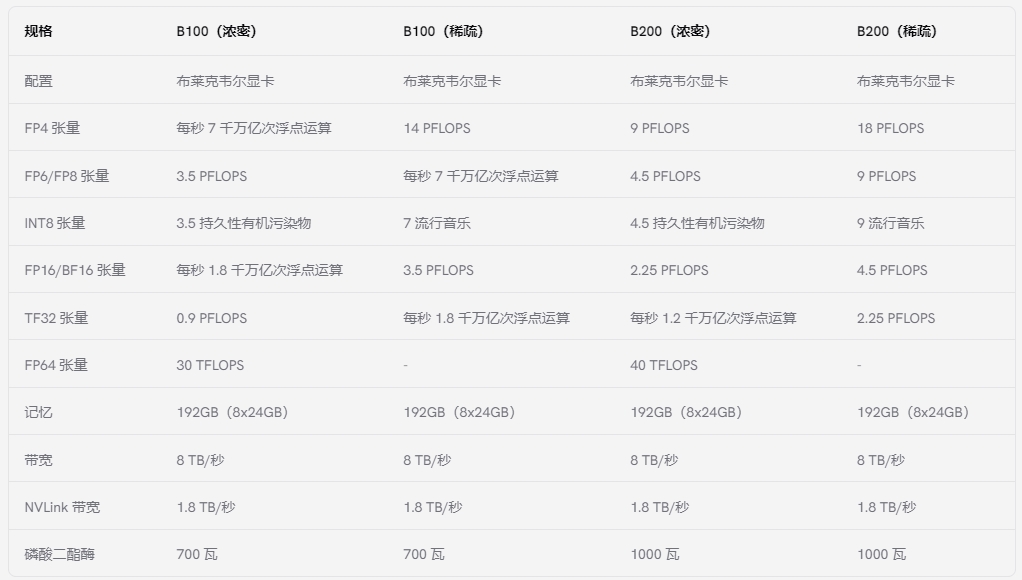
B200 配備 192GB 內(nèi)存,可增強(qiáng)大規(guī)模數(shù)據(jù)處理能力。它支持 8 TB/s 內(nèi)存帶寬和相應(yīng)的 1.8 TB/s NVLink 帶寬,可實(shí)現(xiàn)快速高效的數(shù)據(jù)傳輸。B200 的額定功耗為 1000W,專為在苛刻的計(jì)算環(huán)境中實(shí)現(xiàn)節(jié)能而設(shè)計(jì),在高端性能和功耗之間實(shí)現(xiàn)平衡。
GB200 和 GB200 NVL72
NVIDIA 還發(fā)布了 GB200 Grace Blackwell 超級(jí)芯片。它結(jié)合了兩個(gè) NVIDIA B200 Tensor Core GPU 和一個(gè)NVIDIA Grace CPU超過(guò) 900GB/s 的超低功耗NVLink 芯片到芯片互連。
Grace Blackwell 超級(jí)芯片的芯片到芯片鏈路完全內(nèi)存一致,從而創(chuàng)建了一個(gè)沒(méi)有內(nèi)存本地化的統(tǒng)一芯片。超級(jí)芯片采用 HBM3e 內(nèi)存,提供高達(dá) 384 GB 的容量和 16 TB/s 的帶寬,有助于快速處理數(shù)據(jù)。
它包含一個(gè)解壓縮引擎和多媒體解碼器,基于 72 個(gè) ARM Neoverse V2 內(nèi)核,具有各種緩存級(jí)別(L1、L2 和 L3 緩存),可優(yōu)化數(shù)據(jù)檢索速度。它集成了最新的 NVLink 5.0 和 PCIe Gen 6,支持高速數(shù)據(jù)傳輸。
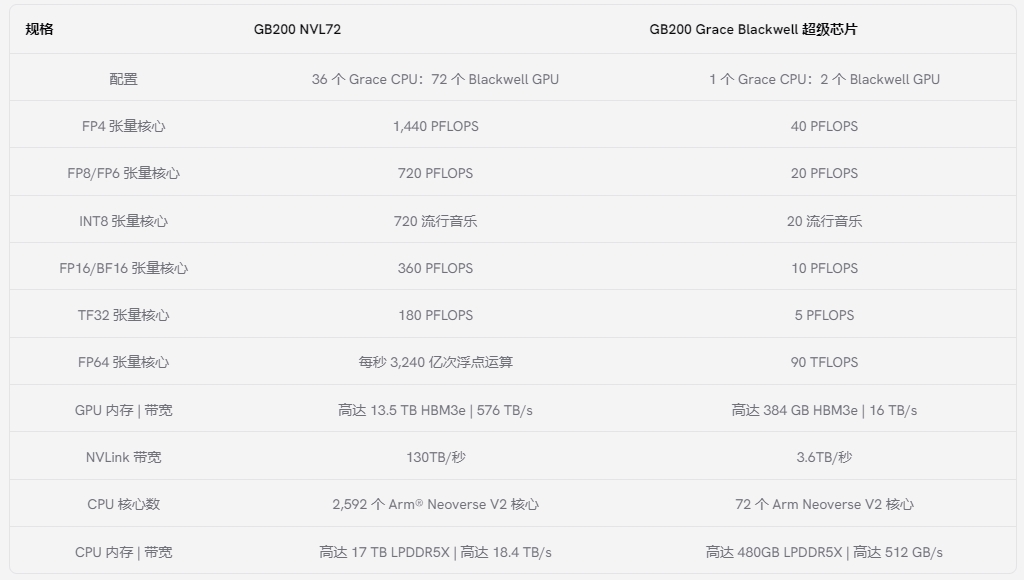
Grace Blackwell 超級(jí)芯片專為可擴(kuò)展性而設(shè)計(jì),支持多實(shí)例 GPU 功能,并且封裝方便服務(wù)器集成。TDP 可配置高達(dá) 2700 W,可根據(jù)計(jì)算需求進(jìn)行能源管理。
在實(shí)際應(yīng)用中,GB200 顯著改善了數(shù)據(jù)庫(kù)處理等計(jì)算任務(wù),速度比傳統(tǒng) CPU 提高了 18 倍,從而降低了能耗和總擁有成本。它加速了對(duì)產(chǎn)品設(shè)計(jì)至關(guān)重要的基于物理的模擬,從而實(shí)現(xiàn)了經(jīng)濟(jì)高效的數(shù)字測(cè)試。對(duì)于 ASIC 設(shè)計(jì)(以 Cadence SpectreX 模擬器為例),它提供了 13 倍的速度提升。此外,在計(jì)算流體力學(xué)方面,GB200 將模擬速度提高了 22 倍,從而提高了工程和設(shè)計(jì)效率。
GB200 NVL72結(jié)合了 36 個(gè) Grace CPU 和 72 個(gè) Blackwell GPU。它是一個(gè)液冷式機(jī)架級(jí) 72-GPU NVLink 域,可以充當(dāng)單個(gè)大型 GPU。它引入了尖端功能和第二代 Transformer Engine,可顯著加速 LLM 推理工作負(fù)載,為資源密集型應(yīng)用程序提供實(shí)時(shí)性能,例如萬(wàn)億參數(shù)語(yǔ)言模型。
推理是生成式 AI 和 LLM 的關(guān)鍵方面之一。它指的是模型在經(jīng)過(guò)訓(xùn)練后,根據(jù)收到的輸入生成或預(yù)測(cè)新數(shù)據(jù)點(diǎn)(標(biāo)記)的階段。此過(guò)程稱為“標(biāo)記生成”。
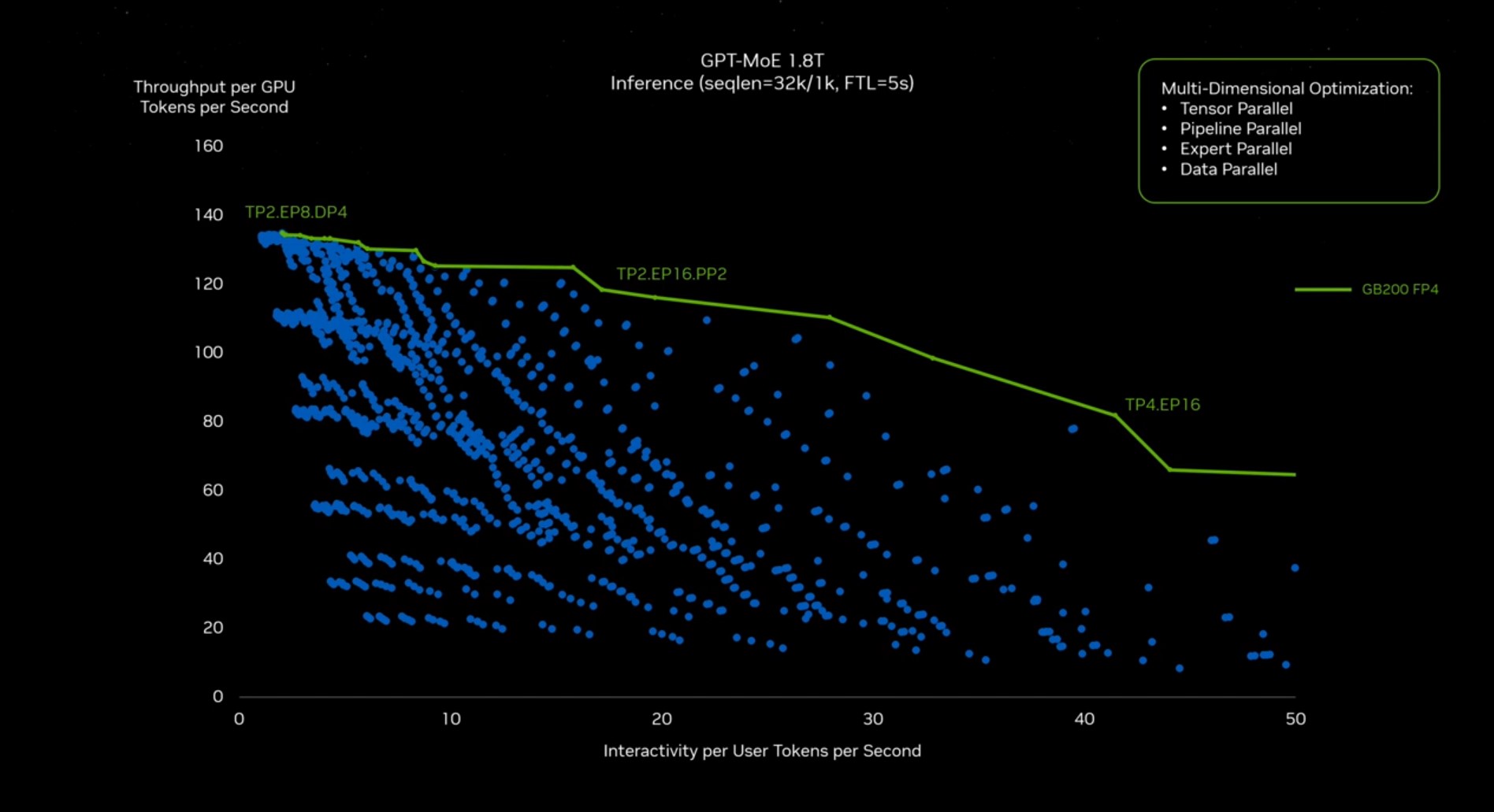
得益于 FP4、張量核心、Transformer 引擎和 NVLink 交換機(jī),GB200 NVL72 可以生成比 Hopper 多 30 倍的令牌,實(shí)現(xiàn) 1.8 TB/s 的 GPU 到 GPU 互連。
GB200 NVL72 專為高級(jí)計(jì)算任務(wù)而設(shè)計(jì),需要高級(jí)網(wǎng)絡(luò)才能發(fā)揮最佳功能。通過(guò)集成 NVIDIA Quantum-X800 InfiniBand、Spectrum-X800 以太網(wǎng)和 BlueField-3 DPU,可提高大型 AI 數(shù)據(jù)中心的性能、效率和安全性。
Quantum-X800 InfiniBand對(duì)于構(gòu)建 AI 計(jì)算框架至關(guān)重要,它能夠在兩級(jí)胖樹(shù)拓?fù)渲羞B接超過(guò) 10,000 個(gè) GPU 單元。此設(shè)置顯著改進(jìn),性能比 NVIDIA 上一代 Quantum-2 提高了五倍。
與此同時(shí),NVIDIA Spectrum-X800和BlueField-3 DPU 平臺(tái)旨在擴(kuò)展整個(gè)數(shù)據(jù)中心的功能。它們提供快速的 GPU 數(shù)據(jù)訪問(wèn),確保多個(gè)用戶(多租戶)的安全環(huán)境,并促進(jìn)簡(jiǎn)化的數(shù)據(jù)中心運(yùn)營(yíng)。這種組合支持 GB200 在高效處理大量 AI 數(shù)據(jù)集方面的作用。
Blackwell 為生成式人工智能帶來(lái)的實(shí)際好處
NVIDIA 的 Blackwell 架構(gòu)旨在加速生成式 AI,大幅縮短訓(xùn)練和推理時(shí)間,從而加快整個(gè)科技行業(yè)的研究和產(chǎn)品開(kāi)發(fā)。從實(shí)際意義來(lái)看,這意味著能夠解決以前計(jì)算成本高昂的問(wèn)題。
隨著 FP4 的引入,訓(xùn)練生成式 AI 時(shí)的準(zhǔn)確度損失最小。FP4 還允許在相同時(shí)間范圍內(nèi)對(duì)模型進(jìn)行更長(zhǎng)時(shí)間的訓(xùn)練,從而提高速度和準(zhǔn)確性。
基于 Blackwell 的 GPU 可用于創(chuàng)建高度詳細(xì)的虛擬現(xiàn)實(shí),這有助于加速多模態(tài) LLM 和機(jī)器人的訓(xùn)練,使其具有更多細(xì)微差別和更好的背景。
此外,NVIDIA 的 B100 和 B200 GPU 可促進(jìn)從材料科學(xué)到醫(yī)學(xué),甚至自動(dòng)駕駛汽車等復(fù)雜領(lǐng)域的進(jìn)步。它們的能力將幫助解決以前無(wú)法解決的挑戰(zhàn),推動(dòng)各行業(yè)的創(chuàng)新和效率。
捷智算平臺(tái)讓您有機(jī)會(huì)優(yōu)先租用 NVIDIA 的最新B100 GPU。與此同時(shí),您可以訪問(wèn)捷智算平臺(tái)的 A100、H100 或 H200 GPU,然后首先通過(guò)云升級(jí)到最新的 GPU 硬件。











